AI has transformed how modern software is built.
From generating boilerplate code to debugging complex systems, tools powered by large language models have become essential in every developer’s workflow. For SaaS founders, indie hackers, and engineering teams, this shift has unlocked a new level of speed and flexibility.
But as adoption grows, a hidden inefficiency is becoming increasingly obvious:
Most AI coding tools waste tokens explaining things you already know.
This is not just a minor annoyance. It is a structural inefficiency that impacts cost, speed, and overall productivity, especially when AI is used in task-based workflows rather than simple chat interactions.
In this article, we will break down:
- Why verbosity is a real problem in AI coding tools
- How token inefficiency affects SaaS development
- What Caveman-style output compression actually does
- Why this matters for task-based execution systems
- How tools like VibeCoderPlanner can benefit from this shift
- What the future of AI-assisted development looks like
The Hidden Cost of Verbose AI Responses
At first glance, verbose responses seem helpful.
When you ask an AI to fix a bug or implement a feature, it often responds with:
- A polite introduction
- Background explanation
- Step-by-step reasoning
- Edge cases
- Final code
For beginners, this is useful.
But for experienced developers or structured workflows, it creates friction.
Example Scenario
You send a simple request:
Fix auth bug where expired JWT still keeps user logged in.
Instead of a direct answer, you receive:
- A breakdown of JWT structure
- Explanation of expiration logic
- Multiple possible causes
- Then finally, a solution
This creates three immediate problems:
1. Increased Token Usage
Every extra word costs tokens.
When repeated across hundreds of tasks, costs scale significantly.
2. Slower Execution
Longer responses take longer to:
- Generate
- Read
- Parse
- Apply
3. Reduced Signal-to-Noise Ratio
When debugging or iterating, you want:
- Clear actions
- Direct fixes
Not paragraphs of explanation.
Why This Problem Gets Worse in SaaS Workflows
The real issue appears when AI is used beyond simple chat.
In modern SaaS development, AI is often used to:
- Generate structured tasks
- Execute them sequentially
- Iterate based on results
This is very different from asking isolated questions.
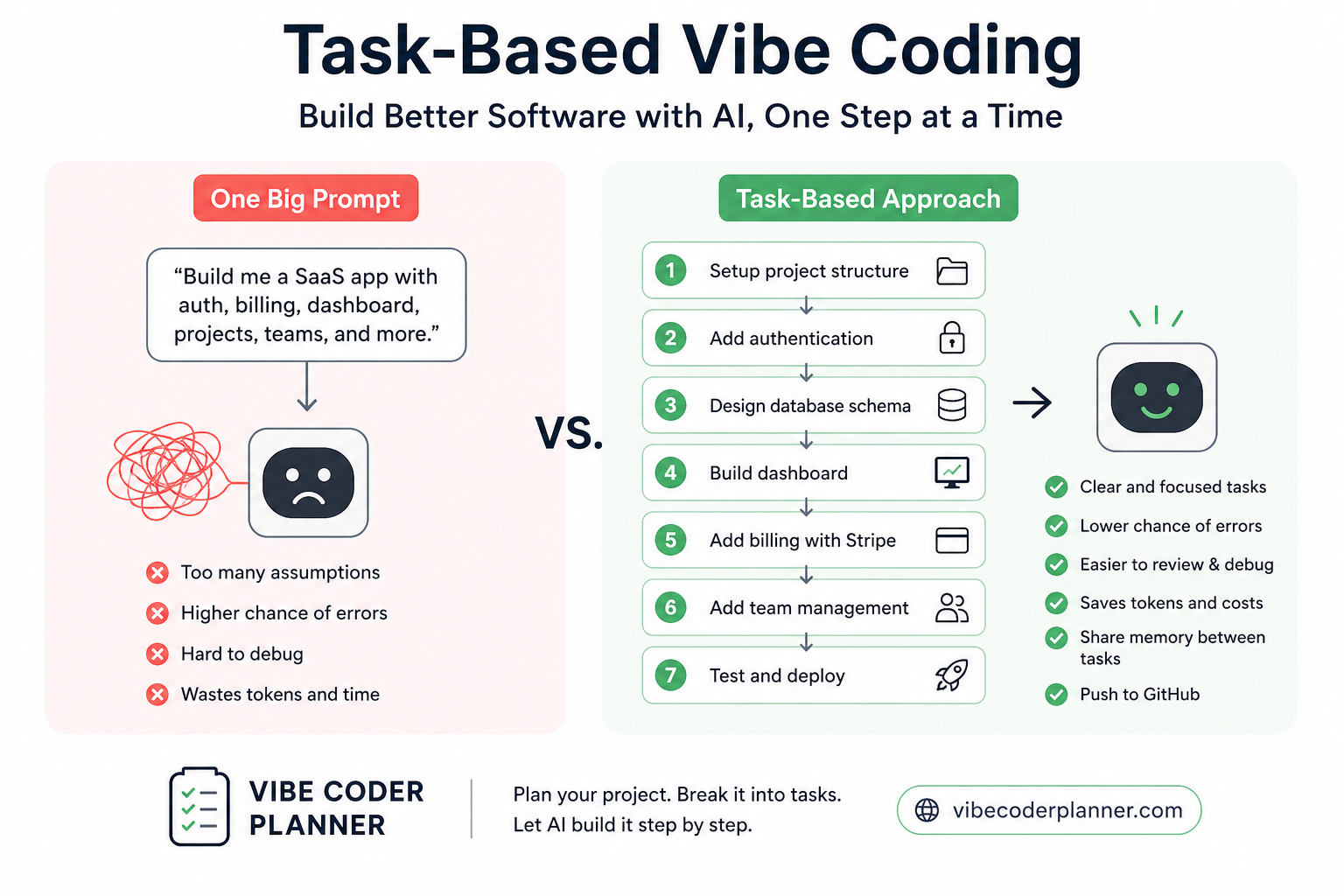
Task-Based Execution Changes Everything
When you run AI in a loop:
- Generate task
- Execute task
- Validate output
- Fix issues
- Repeat
Each step produces output.
Now imagine:
- 50 tasks per feature
- 200 tasks per sprint
- Each task producing verbose responses
You are no longer dealing with occasional verbosity.
You are dealing with systemic inefficiency.
Verbosity Becomes a Tax on Your Workflow
At scale, verbose AI output acts like a hidden tax.
Cost Tax
More tokens per response → higher API costs
Time Tax
Longer responses → slower execution loops
Cognitive Tax
More noise → harder to debug and iterate
This is especially critical for:
- Indie hackers optimizing for cost
- Startups running lean teams
- AI-native SaaS platforms
- Developers building agent-based systems
Introducing Caveman: Output Compression for AI Coding
Caveman is a lightweight but powerful concept.
Instead of improving how AI reasons, it improves how AI communicates results.
Core Idea
Strip everything that is not essential.
Remove:
- Politeness
- Filler words
- Long explanations
- Redundant phrasing
Keep:
- Facts
- Fixes
- Code
- Actions
Example: Normal AI vs Caveman Output
User Prompt
Fix auth bug where expired JWT still keeps user logged in.
Typical AI Output
Sure, I’d be happy to help. This issue usually happens because the token expiration is not being validated correctly on each request. Let me explain how JWT works...
Caveman Output
Bug: expired JWT not checked. Fix: validate exp on every request. Return 401 if expired.
Result
Same outcome.
Significantly fewer tokens.
What Caveman Actually Optimizes
It is important to understand what Caveman does and does not do.
What It Does
- Compresses output text
- Removes unnecessary words
- Keeps technical meaning intact
- Preserves code and structure
What It Does Not Do
- It does not improve reasoning
- It does not change model intelligence
- It does not reduce thinking tokens
It purely optimizes output efficiency.
Token Efficiency: The Missing Optimization Layer
Most developers focus on:
- Prompt engineering
- Model selection
- Tool integrations
Very few optimize:
- Token efficiency per task
This becomes critical when:
- You use AI heavily
- You run workflows continuously
- You pay per token
Why Token Efficiency Matters More in 2026
AI pricing models are still largely based on tokens.
Even with cheaper models emerging, the fundamental equation remains:
More tokens = more cost + more latency
When you scale usage, small inefficiencies compound quickly.
Example Calculation
If you reduce output by 60%:
- 1000 tokens → 400 tokens
- 100 tasks → 60,000 tokens saved
- 1000 tasks → 600,000 tokens saved
This is not a marginal improvement.
It is a structural cost reduction.
From Chat Interfaces to Execution Systems
AI tools started as conversational assistants.
But modern workflows are evolving toward:
- Task-based execution
- Autonomous agents
- Structured pipelines
- Continuous iteration
In this environment:
Chat-style verbosity becomes inefficient.
Execution systems need:
- Precision
- Clarity
- Speed
Why This Fits Perfectly with VibeCoderPlanner
VibeCoderPlanner is built around execution, not conversation.
Workflow Overview
- Describe idea
- Generate tasks
- Execute tasks sequentially
- Iterate
Now apply Caveman-style output:
Before
- Long responses
- Extra explanations
- Slower loops
After
- Direct outputs
- Clear actions
- Faster iteration
The Compounding Effect of Faster Loops
The real advantage is not just saving tokens.
It is accelerating feedback cycles.
Faster loop means:
- More experiments
- More iterations
- Faster product-market fit
Slower loop means:
- Delayed validation
- More friction
- Reduced momentum
In SaaS, speed is often the biggest advantage.
Cleaner Debugging and Better Focus
Verbose AI outputs often hide the real issue.
With compressed output:
- Bugs are easier to identify
- Fixes are easier to apply
- Logs are easier to read
This improves:
- Developer focus
- Debugging speed
- System clarity
Why Most AI Tools Still Get This Wrong
Most tools optimize for:
- User experience
- Friendliness
- Learning support
But not for:
- Execution efficiency
- Token optimization
- High-frequency usage
This creates a mismatch between:
- Casual users
- Power users
The Shift Toward AI Efficiency Engineering
A new layer is emerging in AI development:
Efficiency engineering
This includes:
- Token optimization
- Context compression
- Output structuring
- Cost-aware workflows
Caveman is one example of this shift.
Future of AI Coding Tools
The next generation of tools will focus on:
1. Less Talking, More Doing
AI outputs will become shorter and more actionable
2. Structured Execution
Tasks will replace conversations
3. Cost Awareness
Tools will optimize token usage automatically
4. Adaptive Communication
AI will adjust verbosity based on context
Practical Takeaways
If you are building with AI today:
1. Measure Token Usage
Understand where tokens are being spent
2. Reduce Verbosity
Avoid unnecessary explanations
3. Optimize for Tasks
Think in workflows, not chats
4. Improve Feedback Loops
Faster iteration = better outcomes
Final Thought
You are not paying AI to explain things you already understand.
You are paying it to help you build faster.
Same fix. Less noise. Faster execution.